课程的链接:PARALLEL COMPUTING(Standford CS149)
本文是我个人的学习笔记,适合没那么多时间想要快速过一遍或者英文不好的同学阅读。
Why Parallelism? Why Efficiency?
为什么需要并行?
在过去很长一段时间,处理器性能的提升得益于两方面:
指令级并行(Instruction Level Parallelism)的发展
处理器底层实际上有并行运行的机制,但因为对程序员是不可见的,所以一般人不知道。对于没有依赖关系的指令,现代的处理器会使用并行执行。类似如图所示:
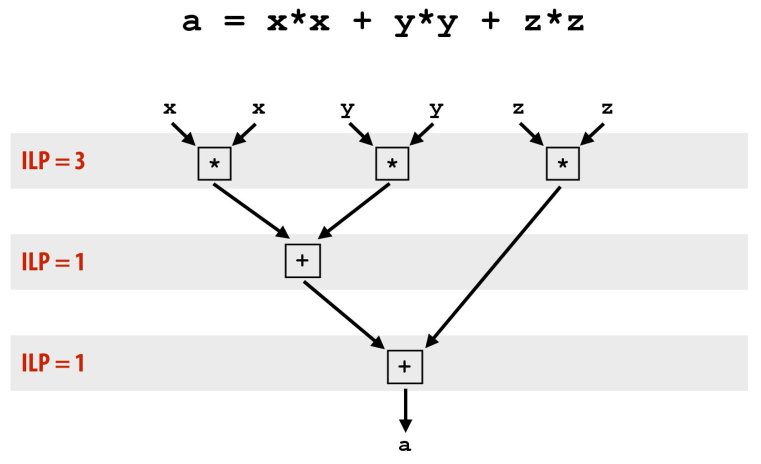
“没有依赖关系”是指,这条指令不需要等待其他指令执行完毕,才能执行。
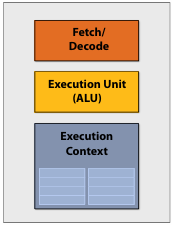
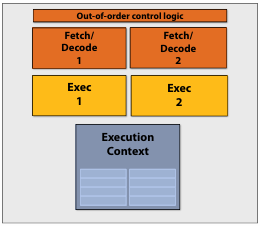
超标量处理器(Superscalar Processor)是指能找到可并行执行的指令,并行运行的处理器,其与普通处理器的区别如图所示:
处理器频率的提升
著名的摩尔定律:处理器的性能每 18 个月就会翻一番。
得益于这些原因,在过去很长一段时间内,软件开发者不需要修改任何程序,仅仅更换硬件就能让程序越来越快。
不幸的是 ILP 的研究已经到顶,CPU 的频率由于要考虑功耗无法再继续提升,如今,处理器的性能提升主要来自于在单位面积中堆叠更多的晶体管:
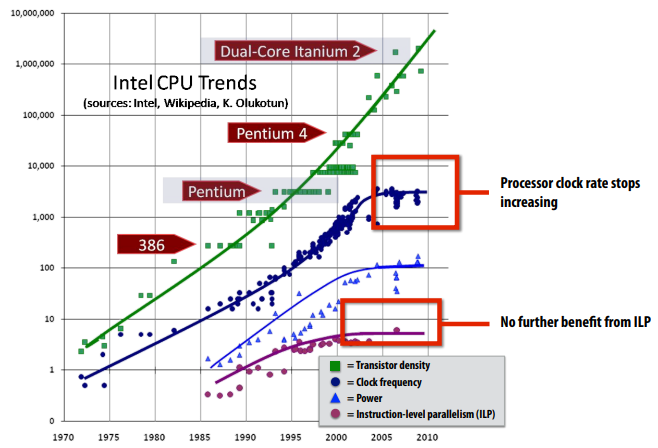
与此同时,多核处理器如今已经成为了主流,程序员必须要编写并行的程序才能利用多核处理器的优势。No more free lunch for software developers!
为什么需要高效?
仅仅编写并行的程序是不行的,程序也必须是高效的。高效也是讨论并行编程的关键主题。
而高效的并行编程往往来自于高效的数据访问。
延迟和停顿
使用 R0 <- mem[R2] 指令访问数据,它发起一个请求,把内存中地址 R2 位置的数据传送给 R0 寄存器。在这个过程中,因为需要等待数据传输完毕,会造成一个延迟(Memory Access Latency):

处理器无法运行下一条指令,因为需要等待上一条指令完成。这种现象叫做 停顿(Stall)。
带宽
时钟(Clock) 是指处理器执行一次运算需要的时间。如图所示:
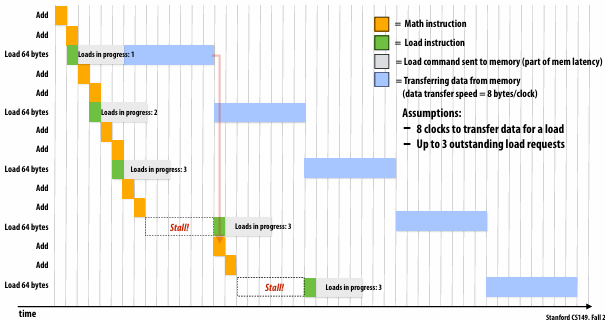
- Math instruction 的运行时长是一次时钟
- Load instruction 的运行时长是不固定的,取决于
内存带宽(Memory Bandwidth)
如果一些 Math instruction 需要依赖于 Load instruction 的结果,就只能等待,于是就造成一次停顿。
大部分时候,处理器都在等待数据被加载,内存带宽几乎决定了处理器的运行速度。相比于从内存中加载数据,The math is “free”.
所以,高性能的并行程序会尽可能减少从内存中请求数据的次数,并且更倾向于重新计算而不是存储/加载值,这一点可以从 GPU 的 Shader 编程中看出来。
缓存
使用缓存(Cache)可以减少停顿的长度。什么是缓存?
缓存是硬件实现,软件程序不需要关注。
缓存只是管理一份数据的拷贝。
在缓存中读取/写入的速度要比内存快得多。
缓存以“缓存行(Cache Lines)” 的形式读取/写入数据。
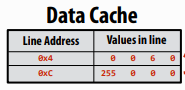
如图所示,每行由一条指向内存的地址和一定长度的数据组成。每次读取/写入以一行为单位。
缓存分为很多级别,级别越高,访问速度越快,但容量越小。各个级别的缓存延迟对比图:
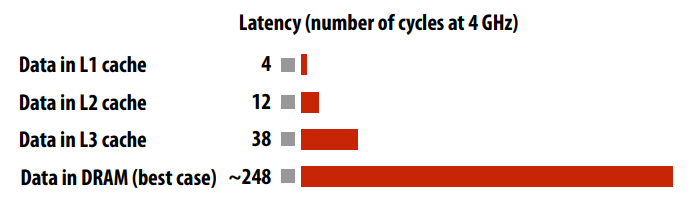
为了尽可能使用速度快的缓存,需要缓存调度策略。比如:Least Recently Used(LRU)。
在一些现代处理器中,存在预测在未来可能会被访问的数据,并提前放入 Cache 中的逻辑。
早期的多核处理器
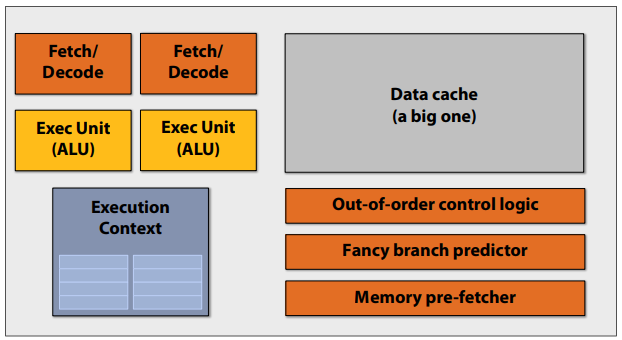
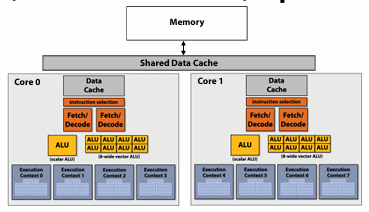
A Modern Multi-Core Processor
SIMD
什么是 SIMD
SIMD(Single Instruction, Multiple Data) 的核心理念是在多个 ALU 中分摊管理指令流的成本/复杂性,把相同的指令广播给所有的 ALU 并行运行。即一条指令处理多个数据,常用于向量或者矩阵的计算。一个支持 SIMD 的处理器的例子:
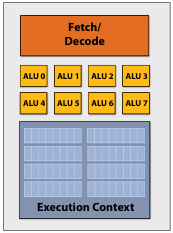
在汇编代码中,有专用的指令:
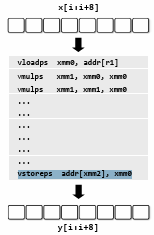
这段代码使用一个 256(8 * 32) 位的寄存器存储 8 个数字,并行计算它们并输出结果。
SIMD 和 ILP 并不同,SIMD 是使用一条指令计算多个数据,而 ILP 则是基于指令的依赖关系去让一些指令可以并行执行。它们可以同时存在。
SIMD 的执行分歧
如果遇到需要条件执行的程序,使用 SIMD 会导致执行分歧:
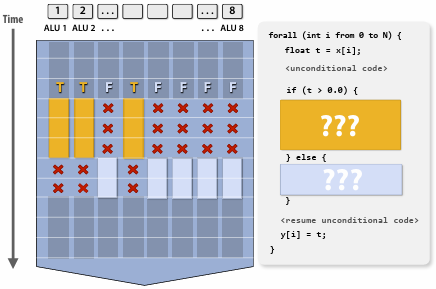
这意味着在一段时间内部分 ALU 是不工作的,导致了性能的浪费。在极端的情况下,可能会导致 CPU 仅使用 $\frac{1}{N}$ 的性能(仅有一个 ALU 工作)。
如何使用 SIMD
- Explicit SIMD,程序员使用显式调用封装了 SIMD 的库
- Implicit SIMD,程序员仅编写高级语言的代码,由特殊的编译器自动生成 SIMD 的汇编指令
线程
线程(Thread),是指在一个处理器核心(Core)中,有多个执行上下文,线程并不能真正并行运行,它只是从一个执行上下文切换到另外一个执行上下文,轮流执行。在其他线程执行的时候,执行完的线程也不会结束,会有很长的停顿。
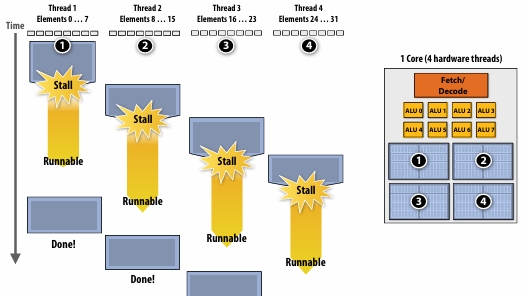
使用线程还需要付出代价:因为存储执行上下文的物理单元也是有限的,更多的线程意味着程序的可用执行上下文会更小。
总结
在现代处理器中,实现并行的方法有:
- Muti-Core
- ILP
- SIMD
- Thread
外加实现高效数据读取/写入的 Cache,它们一起构成了这张现代处理器的并行架构图(同时适用于 CPU 和 GPU):